备份数据库的意义
运维工作到底是什么工作,到底是做什么?
运维工作简单的概括就两件事:
一是保护公司的数据;二是网站7*24小时提供服务。
那么对数据丢失一部分和网站7*24小时提供服务那个更重要呢?
都很重要,只是说相比哪个更为重要?这个具体要看业务个公司。例如:银行、金融行业,数据是最重要的,一条都不能丢,可能宕机停机影响就没那么大。百度搜索,腾讯qq聊天记录丢失了几万条数据,都不算啥。
对于数据来讲,数据最核心的就是数据库数据。
备份单个数据库练习多种参数的使用
MySQL数据库自带了一个很好用的备份命令,就是mysqldump,它的基本使用如下:
| |
备份库
| |
检查备份结果
| |
注:因为导出时的格式没有加字符集,一般恢复到数据库里会正常,只是系统外查看不正常而已。另外,insert是批量插入的方式,这样在恢复时效率很高。
根据查看的结果,我们看到了已备份的表结构语句及插入的数据整合的sql语句,但是中文数据乱码了。
设置字符集参数备份解决乱码问题
查看备份前数据库客户端及服务器端的字符集设置
| |
指定对应的字符集备份,这里为--default-character-set=utf8
| |
备份时加-B参数,增加创建库与选择库
| |
优化配置文件大小减少输出注释(debug调试)
利用mysqldump的--compact参数优化下备份结果
| |
| |
–compact参数说明:
(测试时用的比较多)可以优化输出内容的大小,让容量更少,适合调试。
| |
参数说明:该选项使得输出内容更简介,不包括默认选项中各种注释。有如下几个参数的功能。
--skip-add-drop-table
--no-set-names
--skip-disable-keys
--skip-add-locks
压缩备份的数据
| |
小结:
- 备份数据使用-B参数,会在备份数据中增加建库及use库的语句
- 备份数据使用-B参数,后面可以直接接多个库名。
- 共gzip对备份的数据亚索
- debug时可以用–compact减少输出,但不用于生产
- 指定字符集备份用–default-character-set=utf8(一般不用)
mysqldump的工作原理
利用mysqldump命令备份数据的过程,实际上就是把数据从mysql库里以逻辑的sql语句的形式直接输出或者生成备份的文件的过程。
提示:使用mysqldump是把数据库的数据导出通过sql语句的形式存储,这种备份方式称之为逻辑备份,效率不是很高,一般50G以内的数据。
其他备份方式:物理备份:cp tar(停库),xtrabackup物理热备份。 备份多个库及多个参数
| |
-B参数说明
| |
分库备份
分库备份实际上就是执行一个备份语句备份一个库,如果数据库里有多个库,就执行多条相同的备份单个库的备份语句就可以备份多个库了,注意每个库都可以用对应备份的库作为库名,结尾加.sql。备份多个库的命令如下:
mysqldump -uroot -p111 -B oldboy;
mysqldump -uroot -p111 -B test;
….
….
分库备份法1:
| |
法2:
见分库分表备份视频:http://edu.51cto.com/course/course_id-808.html
分库备份的意义何在?
有时一个企业的数据库里会有多个库,例如(www.bbs,blog),但是出问题的时候很可能是某一个库,如果在备份时把所有的库都备份成了一个数据文件的话,回复某一个库的数据是就比较麻烦了。
备份单个表
语法:
| |
提示:不能加-B参数了,因为库后面就是表了。
企业需求:一个库里有大表有小标,有时可能需要只回复某一个小表,上述的多表备份很难拆开,就想没有分库那样导致恢复某一个小表很麻烦。
那么又如何进行分表备份呢?如下,和分库的思想一样,每执行一条语句备份一个表,生成不同的数据文件即可。如下:
| |
分表备份缺点:文件多,很碎
备一个完整全备,在做一个分库分表备份
脚本批量备份恢复多个SQL文件
面试题:多个库或者多个表备份到一块了,如何恢复单个库或者表?
解答:
- 第三方测试库,导入到库里,然后把需要的备份出来,恢复到正式库里。
- 单表:grep表名 bak.sql>tab_name。
- 实现分库分表备份
备份数据表结构
利用mysqldump -d参数只备份表的结构,例:备份oldboy库的所有表的结构
| |
如果只导出数据则用-t
| |
-T --tab=path:语句与数据分离,数据为文本。
| |
注意只能对表进行分离,对数据库进行分离提示如下:
| |
小结:
-B备份多个库(并添加create和use语句)-d只备份库表结构-t只备份数据(sql语句形式)-T分离表和数据成不同的文件,数据是文本,非SQL语句
刷新binlog参数
mysqldump用于定时对某一时刻的数据的全备份,例如:00点进行备份bak.sql.gz
增量备份:当有数据写入到数据库时,还会同时把更新的SQL语句写入到对应的文件里,这个文件就叫做binlog。
比如说晚上0点做备份, 10点宕机了,0-10点的数据就丢失了
10点前丢失数据需要恢复的数据:
- 00点时刻备份的bak.sql.gz数据还原到数据库,这个时候数据恢复到了00点
- 00-10点数据,就要从binlog里恢复。
binlog作用
记录数据库更新的sql语句,不记录show select等,只是记录对数据库记录变更的二进制文件。
在mysql数据库当中,当你做一个全备之后到出问题的时刻,要想恢复,就是全备+全备之后的所有binlog。
定界binlog
问题:怎么界定备份之后和binlog文件之间连接的很紧密不多也不少。
通过文件的日志点。可以通过-F做一个区分。
只要我们做了备份,然后就刷新binlog,将来恢复的就是130以下的。130以上的包里面就包含了 binlog日志切割:确定全备和增量的结界点-F刷新binlog日志,生成新日志文件,将来增量恢复从这个新日志文件开始。
binglog文件生效需要一个参数:log-bin log-bin=/data/3306/mysql-bin
| |
--master-data 在备份语句里添加 CHANGE MASTER 语句及 binlog 文件及位置点信息
值1,为可执行的CHANGE MASTER语句
值2,为注释的--CHANGE MASTER语句
注:--master-data除了增量恢复确定临界点外,做主从复制时作用更大
| |
| |
| |
| |
mysqldump关键参数说明
| 参数 | 说明 |
|---|---|
| -B | 指定多个库,增加建库语句和use语句。 |
| –compact | 去掉注释,适合调试输出,生产不适用 |
| -A | 备份所有库 |
| -F | 刷新binlog日志,生成新文件,将来增量恢复从这个文件开始。 |
| –master-data | 增加binlog日志文件名及对应的位置点(即CHANGE MASTER语句)。–mater-data=1不注释 2注释 |
| -x –lock-all-tables | |
| -l –lock-tables | lock all tables for read |
| -d | 只备份数据,无表结构,SQL语句形式。 |
| -t | 只备份数据,无库表结构,SQL语句形式。 |
| -T | 库表和数据分离不同文件,数据是文本形式。 |
| –single-transaction | 适合innodb事务数据库备份 |
| -q --quick don’t bufferquery | dump directly to stdout (Defaults to on; use –skip-quick to disable) |
说明:innodb表在备份时,通常启用选线–single-transaction来保证备份的一致性,实际上它的工作原理是设定本次会话的隔离级别为REPEATABLE READ,确保本次会话(dump)时,不会看到其他会话已经提交了的数据。
生产场景不同引擎mysqldump备份命令
myisam引擎企业生产备份,命令(适合所有引擎或混合引擎):
| |
提示:-F也可以不用,与–,master-data有写重复
innodb引擎企业生产备份命令:推荐使用
| |
–master-data作用:
- 使用–master-data=2进行备份文件会增加如下内容:适合普通备份增量恢复
| |
- 使用–maste-data=1进行备份文件会增加如下内容:更适合主从复制
| |
锁表的原理:
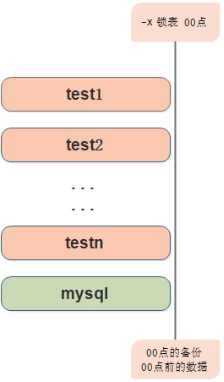
innodb有acid的特性
dump命令是看不到后面生成的数据,只能看到执行这个命令时所有数据之前的这个数据
事务引擎不锁表备份原理:–single-transaction 会话隔离
额外补充:
- mysqldump逻辑备份说明
缺点:效率不是特别高
优点:简单、方便、可靠、迁移。
- 超过50G可选方案
恢复数据到数据库的时候,认为通过SQL语句将数据删除的时候,做主从复制的时候
恢复数据库实战
数据库恢复事项
- 数据恢复和字符集关联很大,如果字符集不正确会导致恢复的数据乱码。
mysql命令以及source命令恢复数据可的原理就是把文件的SQL语句,在数据库里重新执行过程。
- 利用source命令恢复数据库。
进入mysql数据库控制台,mysql -uroot -p登陆后
use database;
然后使用source xx.sql,后面参数为脚本文件(如这里用到的sql)
source 2.sql 这个文件是系统路径,默认是登陆mysql前的系统路径
提示:
source数据恢复和字符集关联很大,如果字符集不正确会导致恢复的数据乱码。
utf8数据库,那么恢复的文件格式需要为utf8无bom头。
利用mysql命令恢复(标准)
| |
假设开发人员让我们插入数据到数据库(可能是邮件发给我们的,内容可能是字符串或是文件)sql文件里没有use db这样的字符,在导入时就要指定数据库名了。
| |
如果在导出时指定-B参数,恢复时无需指定库恢复,为什么?
因为-B参数带了use test;还会有create database test;,而恢复时指定库就类似与use test。
如果mysqldump备份时指定了-B,则恢复可以用如下方法:
| |
提示:此处DbName相当于use Dbname
问题:分库分表备份的数据如何快速恢复呢?
还是通过脚本读指定的库和表,调用mysql命令恢复
| |
针对压缩的备份数据恢复
方法1:
| |
方法2:
| |
或者
| |
| |
分表分库备份脚本
| |