Prepare
Introduction
从2016年8月起,Kubernetes官方提取了与Kubernetes相关的核心源代码,形成了一个独立的项目,即client-go,作为官方提供的go客户端。Kubernetes的部分代码也是基于这个项目的。
client-go 是kubernetes中广义的客户端基础库,在Kubernetes各个组件中或多或少都有使用其功能。。也就是说,client-go可以在kubernetes集群中添加、删除和查询资源对象(包括deployment、service、pod、ns等)。
在了解client-go前,还需要掌握一些概念
- 在客户端验证 API
- 使用证书和使用令牌,来验证客户端
- kubernetes集群的访问模式
使用证书和令牌来验证客户端
在访问apiserver时,会对访问者进行鉴权,因为是https请求,在请求时是需要ca的,也可以使用 -k 使用insecure模式
| |
从错误中可以看出,该请求已通过身份验证,用户是 system:anonymous,但该用户未授权列出对应的资源。而上述请求只是忽略 curl 的https请求需要做的验证,而Kubernetes也有对应验证的机制,这个时候需要提供额外的身份信息来获得所需的访问权限。Kubernetes支持多种身份认证机制,ssl证书也是其中一种。
注:在Kubernetes中没有表示用户的资源。即kubernetes集群中,无法添加和创建。但由集群提供的有效证书的用户都视为允许的用户。Kubernetes从证书中的使用者CN和使用者可选名称中获得用户;然后,RBAC 判断用户是否有权限操作资源。从 Kubernetes1.4 开始,支持用户组,即证书中的O
可以使用 curl 的 --cert 和 --key 指定用户的证书
| |
使用serviceaccount验证客户端身份
使用一个serviceaccount JWT,获取一个SA的方式如下
| |
使用secret来访问API
| |
Pod内部调用Kubernetes API
kubernete会将Kubernetes API地址通过环境变量提供给 Pod,可以通过命令看到
| |
并且还会在将 Kubernetes CA和SA等信息放置在目录 /var/run/secrets/kubernetes.io/serviceaccount/,通过这些就可以从Pod内部访问API
| |
client-go
关于client-go的模块
k8s.io/api
与Pods、ConfigMaps、Secrets和其他Kubernetes 对象所对应的数据结构都在,k8s.io/api,此包几乎没有算法,仅仅是数据机构,该模块有多达上千个用于描述Kubernetes中资源API的结构;通常被client,server,controller等其他的组件使用。
k8s.io/apimachinery
根据该库的描述文件可知,这个库是Server和Client中使用的Kubernetes API共享依赖库,也是kubernetes中更低一级的通用的数据结构。在我们构建自定义资源时,不需要为自定义结构创建属性,如 Kind, apiVersion,name…,这些都是库 apimachinery 所提供的功能。
如,在包 k8s.io/apimachinery/pkg/apis/meta 定义了两个结构 TypeMeta 和 ObjectMeta;将这这两个结构嵌入自定义的结构中,可以以通用的方式兼容对象,如Kubernetes中的资源 Deplyment 也是这么完成的
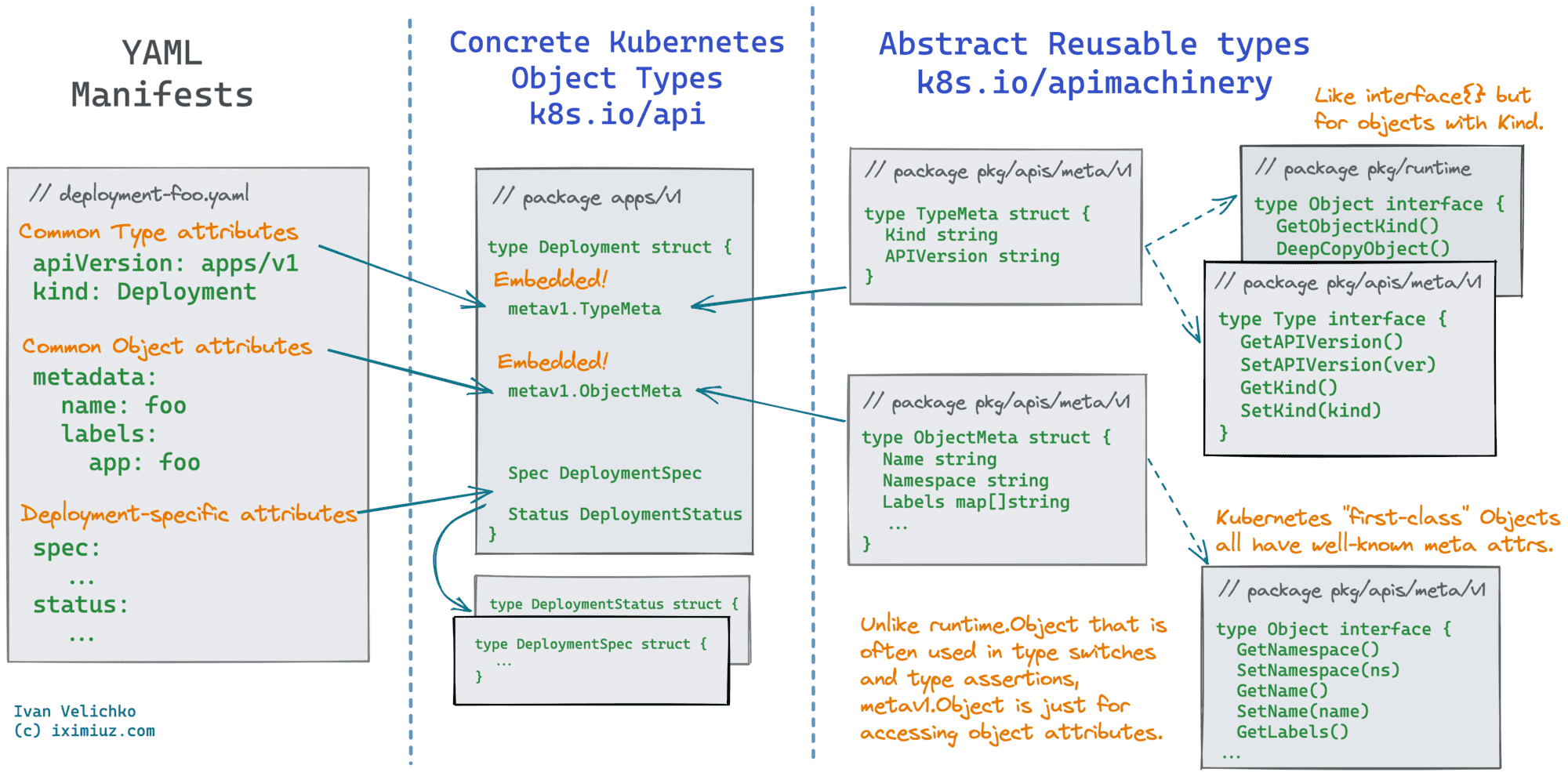
如在 k8s.io/apimachinery/pkg/runtime/interfaces.go 中定义了 interface,这个类为在schema中注册的API都需要实现这个结构
| |

非结构化数据
非结构化数据 Unstructured 是指在kubernete中允许将没有注册为Kubernetes API的对象,作为Json对象的方式进行操作,如,使用非结构化 Kubernetes 对象
| |
非结构化数据的转换
在 k8s.io/apimachinery/pkg/runtime.UnstructuredConverter 中,也提供了将非结构化数据转换为Kubernetes API注册过的结构,参考如何将非结构化对象转换为Kubernetes Object。
install client-go
如何选择 client-go 的版本
对于不同的kubernetes版本使用标签 v0.x.y 来表示对应的客户端版本。具体对应参考 client-go 。
例如使用的kubernetes版本为 v1.18.20 则使用对应的标签 v0.x.y 来替换符合当前版本的客户端库。例如:
| |
官网中给出了client-go的兼容性矩阵,可以很明了的看出如何选择适用于自己kubernetes版本的对应的client-go
✓表示 该版本的client-go与对应的 kubernetes版本功能完全一致+client-go具有 kubernetes apiserver中不具备的功能。-Kubernetes apiserver 具有client-go无法使用的功。
一般情况下,除了对应的版本号完全一致外,其他都存在 功能的+-。
client-go 目录介绍
client-go的每一个目录都是一个go package
kubernetes包含与Kubernetes API所通信的客户端集discovery用于发现kube-apiserver所支持的apidynamic包含了一个动态客户端,该客户端能够对kube-apiserver任意的API进行操作。transport提供了用于设置认证和启动链接的功能tools/cache: 一些 low-level controller与一些数据结构如fifo,reflector等
structure of client-go
RestClient:是最基础的基础架构,其作用是将是使用了http包进行封装成RESTClient。位于rest目录,RESTClient封装了资源URL的通用格式,例如Get()、Put()、Post()Delete()。是与Kubernetes API的访问行为提供的基于RESTful方法进行交互基础架构。- 同时支持Json 与 protobuf
- 支持所有的原生资源和CRD
ClientSet:Clientset基于RestClient进行封装对 Resource 与 version 管理集合;如何创建DiscoverySet:RestClient进行封装,可动态发现 kube-apiserver 所支持的 GVR(Group Version Resource);如何创建,这种类型是一种非映射至clientset的客户端DynamicClient:基于RestClient,包含动态的客户端,可以对Kubernetes所支持的 API对象进行操作,包括CRD;如何创建仅支持json
fakeClient,client-go实现的mock对象,主要用于单元测试。
以上client-go所提供的客户端,仅可使用kubeconfig进行连接。
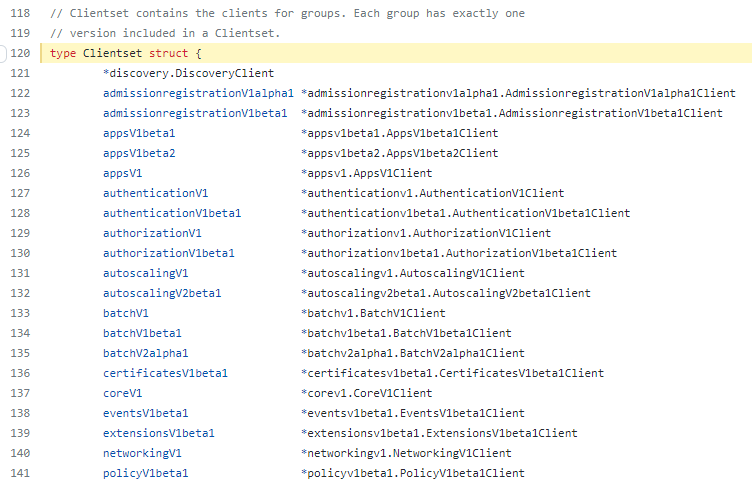
什么是clientset
clientset代表了kubernetes中所有的资源类型,这里不包含CRD的资源,如:
coreextensionsbatch- …
client-go使用
DynamicClient客户端
与 ClientSet 的区别是,可以对任意 Kubernetes 资源进行 RESTful 操作。同样提供管理的方法
最大的不同,ClientSet 需要预先实现每种 Resource 和 Version 的操作,内部的数据都是结构化数据(已知数据结构);DynamicClient 内部实现了 Unstructured,用于处理非结构化的数据(无法提前预知的数据结构),这是其可以处理 CRD 自定义资源的关键。
dynamicClient 实现流程
通过 NewForConfig 实例化 conf 为 DynamicInterface客户端
DynamicInterface客户端中,实现了一个Resource方法即为实现了Interface接口dynamicClient实现了非结构化数据类型与rest client,可以通过其方法将Resource由rest从apiserver中获得api对象,runtime.DeafultUnstructuredConverter.FromUnstructrued转为对应的类型。

注意:GVR 中资源类型 resource为复数。kind:Pod 即为 Pods
| |
Extension
Informer
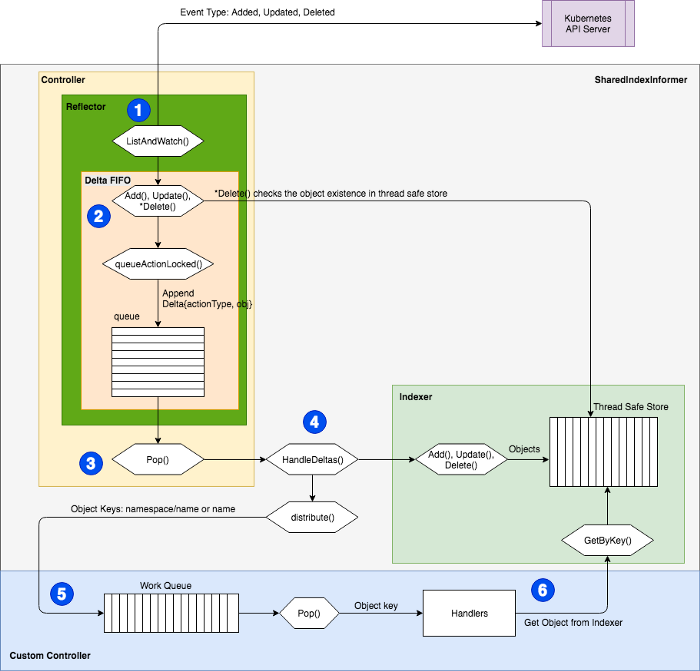
informer是client-go提供的 Listwatcher 接口,主要作为 Controller构成的组件,在Kubernetes中, Controller的一个重要作用是观察对象的期望状态 spec 和实际状态 statue 。为了观察对象的状态,Controller需要向 Apiserver发送请求;但是通常情况下,频繁向Apiserver发出请求的会增加etcd的压力,为了解决这类问题,client-go 一个缓存,通过缓存,控制器可以不必发出大量请求,并且只关心对象的事件。也就是 informer。
从本质上来讲,informer是使用kubernetes API观察其变化,来维护状态的缓存,称为 indexer;并通过对应事件函数通知客户端信息的变化,informer为一系列组件,通过这些组件来实现的这些功能。
- Reflector:与 apiserver交互的组件
- Delta FIFO:一个特殊的队列,Reflector将状态的变化存储在里面
- indexer:本地存储,与etcd保持一致,减轻API Server与etcd的压力
- Processor:监听处理器,通过将监听到的事件发送给对应的监听函数
- Controller:从队列中对整个数据的编排处理的过程
informer的工作模式
首先通过List从Kubernetes API中获取资源所有对象并同时缓存,然后通过Watch机制监控资源。这样,通过informer与缓存,就可以直接和informer交互,而不用每次都和Kubernetes API交互。
另外,informer 还提供了事件的处理机制,以便 Controller 或其他应用程序根据回调钩子函数等处理特定的业务逻辑。因为Informer可以通过List/Watch机制监控所有资源的所有事件,只要在Informer中添加ResourceEventHandler实例的回调函数,如:onadd(obj interface {}), onupdate (oldobj, newobj interface {})和OnDelete( obj interface {}) 可以实现处理资源的创建、更新和删除。 在Kubernetes中,各种控制器都使用了Informer。
分析informer的流程
通过代码 k8s.io/client-go/informers/apps/v1/deployment.go 可以看出,在每个控制器下,都实现了一个 Informer 和 Lister ,Lister就是indexer;
| |
而 Shared Informer 对所有的API组提供一个shared informer
| |
可以看到在 k8s.io/client-go/informers/apps/v1/deployment.go 实现了这个interface
| |
而在对应的 deployment controller中会调用这个Informer 实现对状态的监听;``
| |
Reflector
reflector是client-go中负责监听 Kubernetes API 的组件,也是整个机制中的生产者,负责将 watch到的数据将其放入 watchHandler 中的delta FIFO队列中。也就是吧etcd的数据反射为 delta fifo的数据
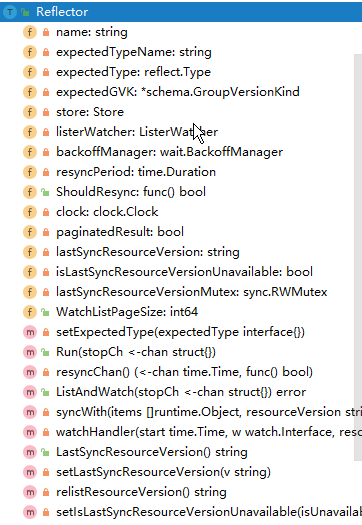
在代码 k8s.io/client-go/tools/cache/reflector.go 中定义了 Reflector 对象
| |
而 方法 NewReflector() 给用户提供了一个初始化 Reflector的接口
在 cotroller.go 中会初始化一个 relector
| |
Reflector下有三个可对用户提供的方法,Run(), ListAndWatch() , LastSyncResourceVersion()
Run() 是对Reflector的运行,也就是对 ListAndWatch() ;
| |
而 ListAndWatch() 则是实际上真实的对Reflector业务的执行
| |
那么在实现时,如 deploymentinformer,会实现 Listfunc和 watchfunc,这其实就是clientset中的操作方法,也是就list与watch
| |
tools/cache/controller.go 是存储controller的配置及实现。
| |
实现这个接口
| |
New() 为给定controller 配置的设置,即为上面的config struct,用来初始化controller对象
NewInformer() :返回一个store(保存数据的最终接口)和一个用于store的controller,同时提供事件的通知(crud)等
NewIndexerInformer():返回一个索引与一个用于索引填充的控制器
控制器的run()的功能实现
| |
总结
在controller的初始化时就初始化了Reflector, controller.Run里面Reflector是结构体初始化时的Reflector,主要作用是watch指定的资源,并且将变化同步到本地的store中。
Reflector接着执行ListAndWatch函数,ListAndWatch第一次会列出所有的对象,并获取资源对象的版本号,然后watch资源对象的版本号来查看是否有被变更。首先会将资源版本号设置为0,list()可能会导致本地的缓存相对于etcd里面的内容存在延迟,Reflector会通过watch的方法将延迟的部分补充上,使得本地缓存数据与etcd的数据保持一致。
controller.Run函数还会调用processLoop函数,processLoop通过调用HandleDeltas,再调用distribute,processorListener.add最终将不同更新类型的对象加入processorListener的channel中,供processorListener.Run使用。
Delta FIFO
通过下图可以看出,Delta FIFO 是位于Reflector中的一个FIFO队列,那么 Delta FIFO 究竟是什么,让我们来进一步深剖。
在代码中的注释可以看到一些信息,根据信息可以总结出
- Delta FIFO 是一个生产者-消费者的队列,生产者是
Reflector,消费者是Pop() - 与传统的FIFO有两点不同
- Delta FIFO
Delta FIFO也是实现了 Queue以及一些其他 interface 的类,

| |
那么delta的类型是,也就是说通常情况下,Delta为一个 string[runtime.object] 的对象
| |
apimachinery/pkg/runtime/interfaces.go

那么此时,已经明白了Delta FIFO的结构,为一个Delta的队列,整个结构如下
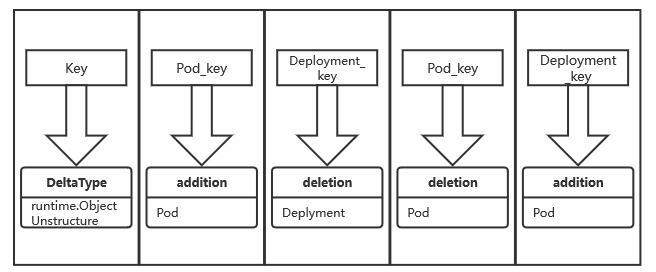
第一步创建一个Delta FIFO
现在版本中,对创建Delta FIFO是通过函数 NewDeltaFIFOWithOptions()
| |
queueActionLocked,Delta FIFO添加操作
这里说下之前说道的,在追加时的操作 queueActionLocked ,如add update delete实际上走的都是这里
| |
在FIFO继承的Stroe的方法中,如,Add, Update等都是需要去重的,去重的操作是通过对比最后一个和倒数第二个值
| |
在函数 dedupDeltas() 中实现的这个
| |
如果b对象的类型是 DeletedFinalStateUnknown 也会认为是一个旧对象被删除,这里在去重时也只是对删除的操作进行去重。
| |
为什么需要去重?什么情况下需合并
代码中开发者给我们留了一个TODO
TODO: is there anything other than deletions that need deduping?
- 取决于Detal FIFO 生产-消费延迟
- 当在一个资源的创建时,其状态会频繁的更新,如 Creating,Runinng等,这个时候会出现大量写入FIFO中的数据,但是在消费端可能之前的并未消费完。
- 在上面那种情况下,以及Kubernetes 声明式 API 的设计,其实多余的根本不关注,只需要最后一个动作如Running,这种情况下,多个内容可以合并为一个步骤
- 然而在代码中,去重仅仅是在Delete状态生效,显然这不可用;那么结合这些得到:
- 在一个工作时间窗口内,如果对于删除操作来说发生多次,与发生一次实际上没什么区别,可以去重
- 但在更新于新增操作时,实际上在对于声明式 API 的设计个人感觉是完全可以做到去重操作。
- 同一个时间窗口内多次操作,如更新,实际上Kubernetes应该只关注最终状态而不是命令式?
Compute Key
上面大概对一些Detal FIFO的逻辑进行了分析,那么对于Detal FIFO如何去计算,也就是说 MetaNamespaceKeyFunc ,这个是默认的KeyFunc,作用是计算Detals中的唯一key。
| |
ObjectMetaAccessor 每个Kubernetes资源都会实现这个对象,如Deployment
| |
那么这个Deltas的key则为集群类型的是资源本身的名字,namespace范围的则为 meta.GetNamespace() + "/" + meta.GetName(),可以在上面代码中看到,这样就可以给Detal生成了一个唯一的key
keyof,用于计算对象的key
| |
Indexer
indexer 在整个 client-go 架构中提供了一个具有线程安全的数据存储的对象存储功能;对于Indexer这里会分析下对应的架构及使用方法。
client-go/tools/cache/index.go 中可以看到 indexer是一个实现了Store 的一个interface
| |
实际上对他的实现是一个 cache,cache是一个KeyFunc与ThreadSafeStore实现的indexer,有名称可知具有线程安全的功能
| |
既然index继承了Store那么,也就是 ThreadSafeStore 必然实现了Store,这是一个基础保证
| |
那么这个indexer structure可以通过图来很直观的看出来

cache的结构
cache中会出现三种数据结构,也可以成为三种名词,为 Index , Indexers , Indices
| |
可以看出:
Index映射到对象,sets.String也是在API中定义的数据类型[string]Struct{},Indexers是这个Index的IndexFunc, 是一个如何计算Index的keyname的函数Indices通过Index 名词拿到对应的对象
这个名词的概念如下,通过图来了解会更加清晰
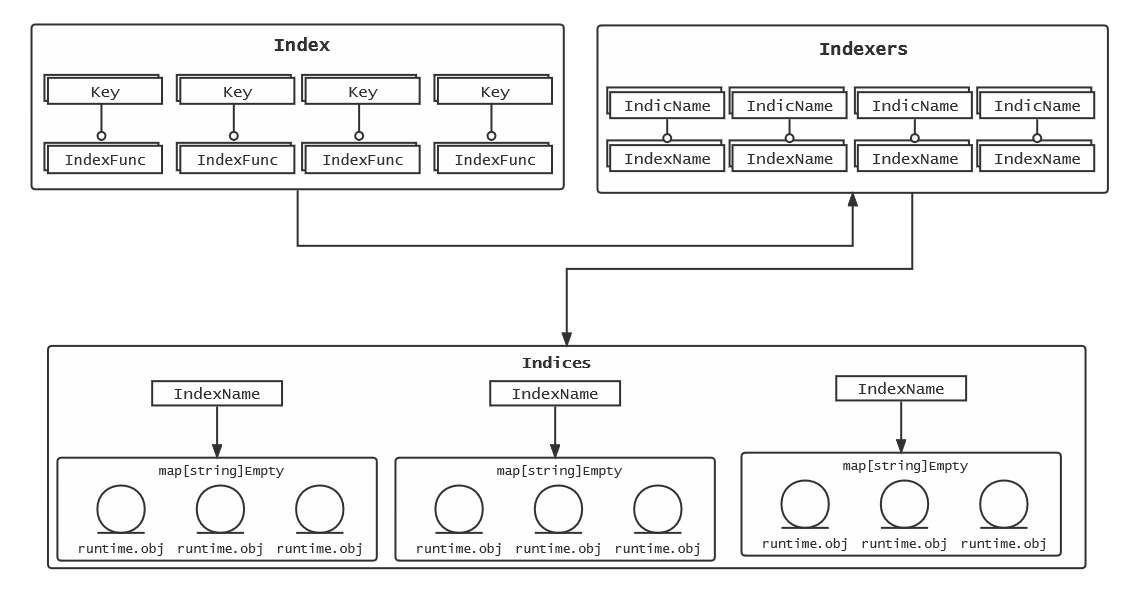
从创建开始
创建一个cache有两种方式,一种是指定indexer,一种是默认indexer
| |
更新操作
在indexer中的更新操作(诸如 add , update ),实际上操作的是 updateIndices, 通过在代码可以看出
tools/cache/thread_safe_store.go 的 77行起,那么就来看下 updateIndices() 具体做了什么
| |
那么通过上面可以了解到了 updateIndices 的逻辑,那么通过对更新函数分析来看看他具体做了什么?这里是add函数,通过一段代码模拟操作来熟悉结构
| |
这里是对add操作以及对updateIndices() 进行操作
| |
总结一下,到这里,可以很明显的看出来,indexer中的三个概念是什么了,前面如果没有看明白话
Index:通过indexer计算出key的名称,值为对应obj的一个集合,可以理解为索引的数据结构- 比如说
Pod:{"nginx-pod1": v1.Pod{Name:Nginx}}
- 比如说
Indexers:这个很简单,就是,对于Index中如何计算每个key的名称;可以理解为分词器,索引的过程Indices通过Index 名词拿到对应的对象,是Index的集合;是将原始数据Item做了一个索引,可以理解为做索引的具体字段- 比如说
Indices["Pod"]{"nginx-pod1": v1.Pod{Name:Nginx}, "nginx-pod2": v1.Pod{Name:Nginx}}
- 比如说
Items:实际上存储的在Indices中的set.String{key:value},中的key=value- 例如:
Item:{"nginx-pod1": v1.Pod{Name:Nginx}, "coredns-depoyment": App.Deployment{Name:coredns}}
- 例如:
删除操作
对于删除操作,在最新版本中是使用了 updateIndices 就是 add update delete全都是相同的方法操作,对于旧版包含1.19- 是单独的一个操作
| |
indexer使用
上面了解了indexer概念,可以通过写代码来尝试使用一些indexer
| |