Overview
K近邻值算法 KNN (K — Nearest Neighbors) 是一种机器学习中的分类算法;K-NN是一种非参数的惰性学习算法。非参数意味着没有对基础数据分布的假设,即模型结构是从数据集确定的。
它被称为惰性算法的原因是,因为它**不需要任何训练数据点来生成模型。**所有训练数据都用于测试阶段,这使得训练更快,测试阶段更慢且成本更高。
如何工作
KNN 算法是通过计算新对象与训练数据集中所有对象之间的距离,对新实例进行分类或回归预测。然后选择训练数据集中距离最小的 K 个示例,并通过平均结果进行预测。
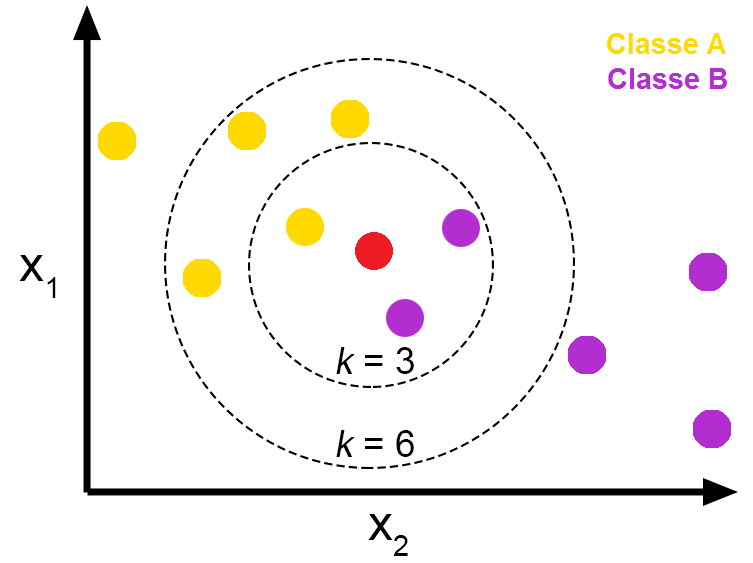
如图所示:一个未分类的数据(红色)和所有其他已分类的数据(黄色和紫色),每个数据都属于一个类别。因此,计算未分类数据与所有其他数据的距离,以了解哪些距离最小,因此当K= 3 (或K= 6 )最接近的数据并检查出现最多的类,如下图所示,与新数据最接近的数据是在第一个圆圈内(圆圈内)的数据,在这个圆圈内还有 3 个其他数据(已经用黄色分类),我们将检查其中的主要类别,会被归类为紫色,因为有2个紫色球,1个黄色球。
KNN算法要执行的步骤
- 将数据分为训练数据和测试数据
- 选择一个值 K
- 确定要使用的距离算法
- 从需要分类的测试数据中选择一个样本,计算到它的 n 个训练样本的距离。
- 对获得的距离进行排序并取 k最近的数据样本。
- 根据 k 个邻居的多数票将测试类分配给该类。
影响KNN算法性能的因素
用于确定最近邻居的距离的算法
用于从 K 近邻派生分类的决策规则
用于对新示例进行分类的邻居数
如何计算距离
测量距离是KNN算法的核心,总结了问题域中两个对象之间的相对差异。比较常见的是,这两个对象是描述主题(例如人、汽车或房屋)或事件(例如购买、索赔或诊断)的数据行。
汉明距离
汉明距离(Hamming Distance)计算两个二进制向量之间的距离,也简称为二进制串 binary strings 或位串 bitstrings ;换句话说,汉明距离是将一个字符串更改为另一个字符串所需的最小替换次数,或将一个字符串转换为另一个字符串的最小错误数。
示例:如一列具有类别 “红色”、“绿色” 和 “蓝色”,您可以将每个示例独热编码为一个位串,每列一个位。
注:独热编码 one-hot encoding:将分类数据,转换成二进制向量表示,这个二进制向量用来表示一种特殊的bit(二进制位)组合,该字节里,仅容许单一bit为1,其他bit都必须为0
如:
apple banana pineapple 1 0 0 0 1 0 0 0 1 100 表示苹果,100就是苹果的二进制向量 010 表示香蕉,010就是香蕉的二进制向量
| |
而red和green之间的距离就是两个等长bitstrings之间bit差(对应符号不同的位置)的总和或平均数,这就是汉明距离
- $Hamming Distance d(a, b)\ =\ sum(xi\ !=\ yi\ for\ xi,\ yi\ in\ zip(x, y))$
上述的实现为:
| |
可以看到字符串之间有两个差异,或者 6 个位位置中有 2 个不同,平均 (2/6) 约为 1/3 或 0.333。
| |
欧几里得距离
欧几里得距离(Euclidean distance) 是计算两个点之间的距离。在计算具体的数值(例如浮点数或整数)的两行数据之间的距离时,您最有可能使用欧几里得距离。
欧几里得距离计算公式为两个向量之间的平方差之和的平方根。
$EuclideanDistance=\sqrt[]{\sum(a-b)^2}$
如果要执行数千或数百万次距离计算,通常会去除平方根运算以加快计算速度。修改后的结果分数将具有相同的相对比例,并且仍然可以在机器学习算法中有效地用于查找最相似的示例。
$EuclideanDistance = sum\ for\ i\ to\ N\ (v1[i]\ –\ v2[i])^2$
| |
曼哈顿距离
曼哈顿距离( Manhattan distance )又被称作出租车几何学 Taxicab geometry;用于计算两个向量之间的距离。
对于描述网格上的对象(如棋盘或城市街区)的向量可能更有用。出租车在城市街区之间采取的最短路径(网格上的坐标)。
粗略地说,欧几里得几何是中学常用的平面几何和立体几何 Plane geometry
曼哈顿距离可以理解为:欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。
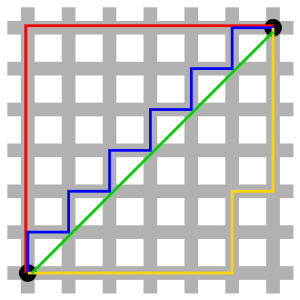
图中: 红、蓝与黄线分别表示所有曼哈顿距离都拥有一样长度(12),绿线表示欧几里得距离 $6×\sqrt2 ≈ 8.48$
对于整数特征空间中的两个向量,应该计算曼哈顿距离而不是欧几里得距离
曼哈顿距离在二维平面的计算公式是,在X轴的亮点
$Manhattandistance\ d(x,y)=\left|x_{1}-x_{2}\right|+\left|y_{1}-y_{2}\right|$
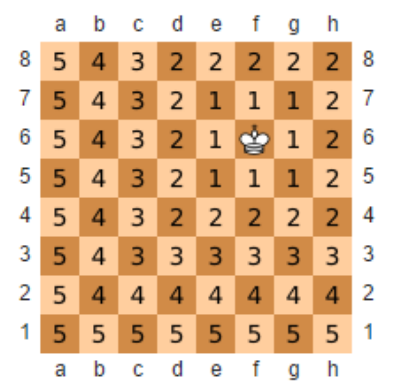
如果所示,描述格子和格子之间的距离可以用曼哈顿距离,如国王移动到右下角的距离是?
$King=|6-8|+|6-1| = 7$
两个向量间的距离可以表示为 $MD\ =\ Σ|Ai – Bi|$
python中的公式可以表示为 :sum(abs(val1-val2) for val1, val2 in zip(a,b))
| |
闵可夫斯基距离
闵可夫斯基距离(Minkowski distance)并不是一种距离而是对是欧几里得距离和曼哈顿距离的概括,用来计算两个向量之间的距离。
闵可夫斯基增并添加了一个参数,称为“阶数”或 p:$d(x,y) = (\sum(|x-y|)^p)^\frac{1}{p}$
在python中的公式:
| |
p 是一个有序的参数,当 $p=1$ 时,计算的是曼哈顿距离。当 $p=2$ 时,计算的是欧几里得距离。
在实现使用距离度量的机器学习算法时,通常会使用闵可夫斯基距离,因为可以通过调整参数“ p ”控制用于向量的距离度量算法的类型。
| |
KNN算法实现
Prerequisite
首先会用示例来实现KNN算法的每个步骤,并加以分析,然后将所有步骤关联在在一起,形成一个适用于真实数据集的实现。
KNN在实现起来主要有三个步骤:
- 计算距离(这里选择欧几里得距离)
- 获得临近邻居
- 做出预测
这三个步骤是KNN算法用以解决分类和回归预测建模问题的基础知识
计算距离
第一步计算数据集中两行之间的距离。在数据集中的数据行主要由数字组成,计算两行或数字向量之间的距离的一种简单方法是画一条直线。这在 2D 或 3D 平面中都是很好地选择,并且可以很好地扩展到更高的维度。
这里使用的是比较流行的计算距离的算法,欧几里得距离来计算两个向量之间的直线距离。欧几里得距离的公式是,两个向量的平方差的平方根,$Euclidean\ Distance=\sqrt[]{\sum(a-b)^2}$ ;在python中可以表示为:sqrt(sum i to N (x1 – x2)^2) ;其中 x1 是第一行数据,x2 是第二行数据,i 表示特定列的索引,因为可能需要对所有行进行计算。
在欧几里得距离中,值越小,两条记录就越相似; 0 表示两条记录之间没有差异。
那么使用python实现一个计算欧几里得距离的算法
| |
准备一部分测试数据,来对测试距离算法
| |
那么来测试这些数据,需要做到的是第一行与所有行之间的距离,对于第一行与自己的距离应该为0
| |
获取最近邻居
数据集中新数据的邻居是k个最接近的实例(行),这个实例由距离定义。现在诞生的问题:如何找到最近的邻居?以及怎么找到最近的邻居?
为了在数据集中找到 K 的邻居,首先必须计算数据集中每条记录与新数据之间的距离。
有了距离之后,必须按照 K 的距离对训练集中的所有实例排序。然后选择前 k 个作为最近的邻居。
这里实现起来是通过将数据集中每条记录的距离作为一个元组来跟踪,通过对元组列表进行排序(距离降序),然后检索最近邻居。下面是一个实现这些步骤的函数
| |
下面是完整的示例
| |
可以看到,运行后会将数据集中最相似的 3 条记录按相似度顺序打印。和预测的一样,第一个记录与其本身最相似,并且位于列表的顶部。
预测结果
预测结果在这里指定是,通过分类拿到了最近的邻居的实例,对邻居进行分类,找到邻居中最大类别的一类,作为预测值。这里使用的是对邻居值执行 max() 来实现这一点,下面是实现方式
| |
下面是完整的示例
| |
运行结果打印了预期分类与从数据集中 3 个相进邻居预测结果是一直的。
鸢尾花种实例
这里使用的是 Iris Flower Species 数据集。
鸢尾花数据集是根据鸢尾花的测量值预测花卉种类。这是一个多类分类问题。每个类的观察数量是平衡的。有 150 个观测值,有 4 个输入变量和 1 个输出变量。变量名称如下:
- 萼片长度以厘米为单位。
- 萼片宽度以厘米为单位。
- 花瓣长度以厘米为单位。
- 花瓣宽度以厘米为单位。
- 真实类型
更多的关于数据集的说明可以参考:Iris-databases数据集的说明
Prerequisite
实验的步骤大概分为如下:
- 加载数据集并将数据转换为可用于均值和标准差计算的数字。将属性转为float,将类别转换为int。
- 使 5折的K折较差验证(K-Fold CV)评估该算法。
Start
| |
上述是对整个数据集的预测百分比,也可以对对应的类的信息进行输出
首先在类别转换函数 str_column_to_int 中增加打印方法
| |
然后在定义一个新的实例,这个实例是用于预测的信息 row = [5.7,2.9,4.2,1.3] ; 然后修改需要预测的数据,进行预测
| |
通过预测,可以看出预测结果属于第 1 类,就知道该花为 Iris-setosa 。