调度框架 [1]
本文基于 kubernetes 1.24 进行分析
调度框架(Scheduling Framework)是Kubernetes 的调度器 kube-scheduler 设计的的可插拔架构,将插件(调度算法)嵌入到调度上下文的每个扩展点中,并编译为 kube-scheduler
在 kube-scheduler 1.22 之后,在 pkg/scheduler/framework/interface.go 中定义了一个 Plugin 的 interface,这个 interface 作为了所有插件的父级。而每个未调度的 Pod,Kubernetes 调度器会根据一组规则尝试在集群中寻找一个节点。
| |
下面会对每个算法是如何实现的进行分析
在初始化 scheduler 时,会创建一个 profile,profile是关于 scheduler 调度配置相关的定义
| |
关于 profile 的实现,则为 KubeSchedulerProfile,也是作为 yaml生成时传入的配置
| |
对于 profile.NewMap 就是根据给定的配置来构建这个framework,因为配置可能是存在多个的。而 Registry 则是所有可用插件的集合,内部构造则是 PluginFactory ,通过函数来构建出对应的 plugin
| |
可以看到最终返回的是一个 Framework 。那么来看下这个 Framework
Framework 是一个抽象,管理着调度过程中所使用的所有插件,并在调度上下文中适当的位置去运行对应的插件
| |
而实现这个抽象的则是 frameworkImpl;frameworkImpl 是初始化与运行 scheduler plugins 的组件,并在调度上下文中会运行这些扩展点
| |
那么来看下 Registry ,Registry 是作为一个可用插件的集合。framework 使用 registry 来启用和对插件配置的初始化。在初始化框架之前,所有插件都必须在注册表中。表现形式就是一个 map[];key 是插件的名称,value是 PluginFactory 。
| |
而在 pkg\scheduler\framework\plugins\registry.go 中会将所有的 in-tree plugin 注册进来。通过 NewInTreeRegistry 。后续如果还有插件要注册,可以通过 WithFrameworkOutOfTreeRegistry 来注册其他的插件。
| |
这里插入一个题外话,关于 in-tree plugin
在这里没有找到关于,kube-scheduler ,只是找到有关的概念,大概可以解释为,in-tree表示为随kubernetes官方提供的二进制构建的 plugin 则为
in-tree,而独立于kubernetes代码库之外的为out-of-tree[3] 。这种情况下,可以理解为,AA则是out-of-tree而Pod,DeplymentSet等是in-tree。
接下来回到初始化 scheduler ,在初始化一个 scheduler 时,会通过NewInTreeRegistry 来初始化
| |
接下来在调度上下文 scheduleOne 中 schedulePod 时,会通过 framework 调用对应的插件来处理这个扩展点工作。具体的体现在,pkg\scheduler\schedule_one.go 中的预选阶段
| |
与其他扩展点部分,在调度上下文 scheduleOne 中可以很好的看出,功能都是 framework 提供的。
| |
插件 [4]
插件(Plugins)(也可以算是调度策略)在 kube-scheduler 中的实现为 framework plugin,插件API的实现分为两个步骤**:register** 和 configured,然后都实现了其父方法 Plugin。然后可以通过配置(kube-scheduler --config 提供)启动或禁用插件;除了默认插件外,还可以实现自定义调度插件与默认插件进行绑定。
| |
插件的载入过程
在 scheduler 被启动时,会 scheduler.New(cc.Client.. 这个时候会传入 profiles,整个的流如下:
NewScheduler:kubernetes/cmd/kube-scheduler/app/server.goprofile.NewMap:kubernetes/pkg/scheduler/scheduler.gonewProfile:kubernetes/pkg/scheduler/scheduler.go
frameworkruntime.NewFramework:kubernetes/pkg/scheduler/framework/runtime/framework.gopluginsNeeded:kubernetes/pkg/scheduler/framework/runtime/framework.go
NewScheduler
我们了解如何 New 一个 scheduler 即为 Setup 中去配置这些参数,
| |
profile.NewMap
在 scheduler.New 中,会根据配置生成profile,而 profile.NewMap 会完成这一步
| |
NewFramework
newProfile 返回的则是一个创建好的 framework
| |
最终会走到 pluginsNeeded,这里会根据配置中开启的插件而返回一个插件集,这个就是最终在每个扩展点中药执行的插件。
| |
插件的执行
在对插件源码部分分析,会找几个典型的插件进行分析,而不会对全部的进行分析,因为总的来说是大同小异,分析的插件有 NodePorts,NodeResourcesFit,podtopologyspread
NodePorts
这里以一个简单的插件来分析;NodePorts 插件用于检查Pod请求的端口,在节点上是否为空闲端口。
NodePorts 实现了 FilterPlugin 和 PreFilterPlugin
PreFilter 将会被 framework 中 PreFilter 扩展点被调用。
| |
Filter 将会被 framework 中 Filter 扩展点被调用。
| |
New ,初始化新插件,在 register 中注册得
| |
在调用中,如果有任何一个插件返回错误,则跳过该扩展点注册得其他插件,返回失败。
| |
返回得状态是一个 Status 结构体,该结构体表示了插件运行的结果。由 Code、reasons、(可选)err 和 failedPlugin (失败的那个插件名)组成。当 code 不是 Success 时,应说明原因。而且,当 code 为 Success 时,其他所有字段都应为空。nil 状态也被视为成功。
| |
NodeResourcesFit [5]
NodeResourcesFit 扩展检查节点是否拥有 Pod 请求的所有资源。分数可以使用以下三种策略之一,扩展点为:preFilter, filter,score
LeastAllocated(默认)MostAllocatedRequestedToCapacityRatio
Fit
NodeResourcesFit PreFilter 可以看到调用得 computePodResourceRequest
| |
computePodResourceRequest 这里有一个注释,总体解释起来是这样得:computePodResourceRequest ,返回值( framework.Resource)覆盖了每一个维度中资源的最大宽度。因为将按照 init-containers , containers 得顺序运行,会通过迭代方式收集每个维度中的最大值。计算时会对常规容器的资源向量求和,因为containers 运行会同时运行多个容器。计算示例为:
| |
在维度1中(InitContainers)所需资源最大值时,CPU=2, Memory=3G;而维度2(Containers)所需资源最大值为:CPU=2, Memory=1G;那么最终结果为 CPU=3, Memory=3G,因为在维度1,最大资源时Memory=3G;而维度2最大资源是CPU=1+2, Memory=1+1,取每个维度中最大资源最大宽度即为 CPU=3, Memory=3G。
下面则看下代码得实现
| |
leastAllocate
LeastAllocated 是 NodeResourcesFit 的打分策略 ,LeastAllocated 打分的标准是更偏向于请求资源较少的Node。将会先计算出Node上调度的pod请求的内存、CPU与其他资源的百分比,然后并根据请求的比例与容量的平均值的最小值进行优先级排序。
计算公式是这样的:$\frac{\frac{cpu((capacity-requested) \times MaxNodeScore \times cpuWeight)}{capacity} + \frac{memory((capacity-requested) \times MaxNodeScore \times memoryWeight}{capacity}) + …}{weightSum}$
下面来看下实现
| |
leastRequestedScore 计算标准为未使用容量的计算范围为 0~MaxNodeScore,0 为最低优先级,MaxNodeScore 为最高优先级。未使用的资源越多,得分越高。
| |
Topology [6]
Concept
在对 podtopologyspread 插件进行分析前,先需要掌握Pod拓扑的概念。
Pod拓扑(Pod Topology)是Kubernetes Pod调度机制,可以将Pod分布在集群中不同 Zone ,以及用户自定义的各种拓扑域 (topology domains)。当有了拓扑域后,用户可以更高效的利用集群资源。
如何来解释拓扑域,首先需要提及为什么需要拓扑域,在集群有3个节点,并且当Pod副本数为2时,又不希望两个Pod在同一个Node上运行。在随着扩大Pod的规模,副本数扩展到到15个时,这时候最理想的方式是每个Node运行5个Pod,在这种背景下,用户希望对集群中Zone的安排为相似的副本数量,并且在集群存在部分问题时可以更好的自愈(也是按照相似的副本数量均匀的分布在Node上)。在这种情况下Kubernetes 提供了Pod 拓扑约束来解决这个问题。
定义一个Topology
| |
参数的描述:
- maxSkew:Required,Pod分布不均的程度,并且数字必须大于零
- 当
whenUnsatisfiable: DoNotSchedule,则定义目标拓扑中匹配 pod 的数量与 全局最小值(拓扑域中的标签选择器匹配的 pod 的最小数量 )maxSkew之间的最大允许差异。例如有 3 个Zone,分别具有 2、4 和 5 个匹配的 pod,则全局最小值为 2 - 当
whenUnsatisfiable: ScheduleAnyway,scheduler 会为减少倾斜的拓扑提供更高的优先级。
- 当
- minDomains:optional,符合条件的域的最小数量。
- 如果不指定该选项
minDomains,则约束的行为minDomains: 1。 minDomains必须大于 0。minDomains与whenUnsatisfiable一起时为whenUnsatisfiable: DoNotSchedule。
- 如果不指定该选项
- topologyKey:Node label的key,如果多个Node都使用了这个lable key那么 scheduler 将这些 Node 看作为相同的拓扑域。
- whenUnsatisfiable:当 Pod 不满足分布的约束时,怎么去处理
DoNotSchedule(默认)不要调度。ScheduleAnyway仍然调度它,同时优先考虑最小化倾斜节点
- labelSelector:查找匹配的 Pod label选择器的node进行技术,以计算Pod如何分布在拓扑域中
对于拓扑域的理解
对于拓扑域,官方是这么说明的,假设有一个带有以下lable的 4 节点集群:
| |
那么集群拓扑如图:

假设一个 4 节点集群,其中 3个label被标记为foo: bar的 Pod 分别位于Node1、Node2 和 Node3:
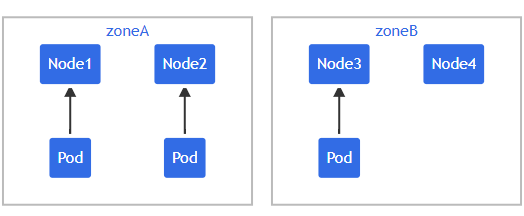
这种情况下,新部署一个Pod,并希望新Pod与现有Pod跨 Zone均匀分布,资源清单文件如下:
| |
这个清单对于拓扑域来说,topologyKey: zone 表示对Pod均匀分布仅应用于已标记的节点(如 foo: bar),将会跳过没有标签的节点(如zone: <any value>)。如果 scheduler 找不到满足约束的方法,whenUnsatisfiable: DoNotSchedule 设置的策略则是 scheduler 对新部署的Pod保持 Pendding
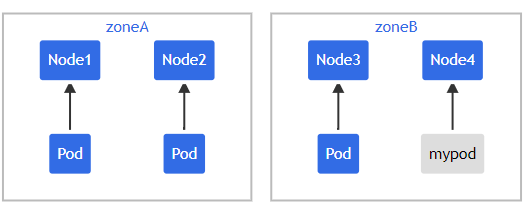
如果此时 scheduler 将新Pod 调度至 $Zone_A$,此时Pod分布在拓扑域间为 $[3,1]$ ,而 maxSkew 配置的值是1。此时倾斜值为 $Zone_A - Zone_B = 3-1=2$,不满足 maxSkew=1,故这个Pod只能被调度到 $Zone_B$。
此时Pod调度拓扑图为图3或图4
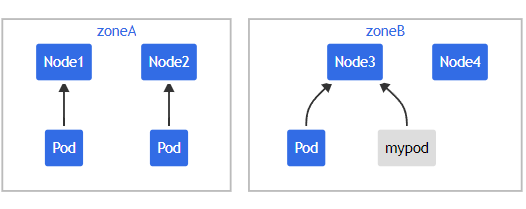
如果需要将Pod调度到 $Zone_A$ ,可以按照如下方式进行:
- 修改
maxSkew=2 - 修改
topologyKey: node而不是Zone,这种模式下可以将 Pod 均匀分布在Node而不是Zone之间。 - 修改
whenUnsatisfiable: DoNotSchedule为whenUnsatisfiable: ScheduleAnyway确保新的Pod始终可被调度
下面再通过一个例子增强对拓扑域了解
多拓扑约束
设拥有一个 4 节点集群,其中 3 个现有 Pod 标记 foo: bar 分别位于 node1、node2 和 node3
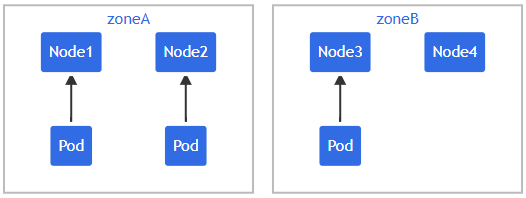
部署的资源清单如下:可以看出拓扑分布约束配置了多个
| |
在这种情况下,为了匹配第一个约束条件,新Pod 只能放置在 $Zone_B$ ;而就第二个约束条件,新Pod只能调度到 node4。在这种配置多约束条件下, scheduler 只考虑满足所有约束的值,因此唯一有效的是 node4。
如何为集群设置一个默认拓扑域约束
默认情况下,拓扑域约束也作 scheduler 的为 scheduler configurtion 中的一部分参数,这也意味着,可以通过profile为整个集群级别指定一个默认的拓扑域调度约束,
| |
默认约束策略
如果在没有配置集群级别的约束策略时,kube-scheduler 内部 topologyspread 插件提供了一个默认的拓扑约束策略,大致上如下列清单所示
| |
上述清单中内容可以在 pkg\scheduler\framework\plugins\podtopologyspread\plugin.go
| |
可以通过在配置文件中留空,来禁用默认配置
defaultConstraints: []defaultingType: List
| |
通过源码学习Topology
podtopologyspread 实现了4种扩展点方法,包含 filter 和 score
PreFilter
可以看到 PreFilter 的核心为 calPreFilterState
| |
calPreFilterState 主要功能是用在计算如何在拓扑域中分布Pod,首先看段代码时,需要掌握下属几个概念
| |
preFilterState
| |
criticalPaths
| |
单元测试中的测试案例,具有两个约束条件的场景,通过表格来解析如下:
Node列表与标签如下表:
| Node Name | 🏷️Lable-zone | 🏷️Lable-node |
|---|---|---|
| node-a | zone1 | node-a |
| node-b | zone1 | node-b |
| node-x | zone2 | node-x |
| node-y | zone2 | node-y |
Pod列表与标签如下表:
| Pod Name | Node | 🏷️Label |
|---|---|---|
| p-a1 | node-a | foo: |
| p-a2 | node-a | foo: |
| p-b1 | node-b | foo: |
| p-y1 | node-y | foo: |
| p-y2 | node-y | foo: |
| p-y3 | node-y | foo: |
| p-y4 | node-y | foo: |
对应的拓扑约束
| |
那么整个分布如下:
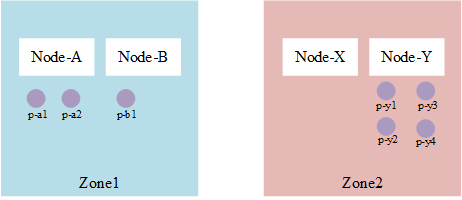
实现的测试代码如下
| |
update
update 函数实际上时用于计算 criticalPaths 中的第一位始终保持为是一个最小Pod匹配值
| |
综合来讲 Prefilter 主要做的工作是。循环所有的节点,先根据 NodeAffinity 或者 NodeSelector 进行过滤,然后根据约束中定义的 topologyKeys (拓扑划分的依据) 来选择节点。
接下来会计算出每个拓扑域下的拓扑对(可以理解为子域)匹配的 Pod 数量,存入 TpPairToMatchNum 中,最后就是要把所有约束中匹配的 Pod 数量最小(第二小)匹配出来的路径(代码是这么定义的,理解上可以看作是分布图)放入 TpKeyToCriticalPaths 中保存起来。整个 preFilterState 保存下来传递到后续的 filter 插件中使用。
Filter
在 preFilter 中 最后的计算结果会保存在 CycleState 中
| |
Filter 主要是从 PreFilter 处理的过程中拿到状态 preFilterState,然后看下每个拓扑约束中的 MaxSkew 是否合法,具体的计算公式为:$matchNum + selfMatchNum - minMatchNum$
matchNum:Prefilter 中计算出的对应的拓扑分布数量,可以在Prefilter中参考对应的内容if tpCount, ok := s.TpPairToMatchNum[pair]; ok {
selfMatchNum:匹配到label的数量,匹配到则是1,否则为0minMatchNum:获的Prefilter中计算出来的最小匹配的值
| |
minMatchNum
| |
PreScore
与 Filter 类似, PreScore 也是类似 PreFilter 的构成。 initPreScoreState 来完成过滤。
有了 PreFilter 基础后,对于 Score 来说大同小异
| |
与Filter中Update使用的函数一样,这里也会到这一步,这里会构建出TopologySpreadConstraints,因为约束是不确定的
| |
Score
| |
在 Framework 中会运行 ScoreExtension ,即 NormalizeScore
| |
NormalizeScore 会为所有的node根据之前计算出的权重进行打分
| |
到此,对于pod拓扑插件功能大概可以明了了,
- Filter 部分(
PreFilter,Filter)完成拓扑对(Topology Pair)划分 - Score部分(
PreScore,Score,NormalizeScore)主要是对拓扑对(可以理解为拓扑结构划分)来选择一个最适合的pod的节点(即分数最优的节点)
而在 scoring_test.go 给了很多用例,可以更深入的了解这部分算法
Reference
[3] in tree VS out of tree volume plugins