Overview
本文将深入讲解 如何扩展 Kubernetes scheduler 中各个扩展点如何使用,与扩展scheduler的原理,这些是作为扩展 scheduler 的所需的知识点。最后会完成一个实验,基于网络流量的调度器。
kubernetes调度配置
kubernetes集群中允许运行多个不同的 scheduler ,也可以为Pod指定不同的调度器进行调度。在一般的Kubernetes调度教程中并没有提到这点,这也就是说,对于亲和性,污点等策略实际上并没有完全的使用kubernetes调度功能,在之前的文章中提到的一些调度插件,如基于端口占用的调度 NodePorts 等策略一般情况下是没有使用到的,本章节就是对这部分内容进行讲解,这也是作为扩展调度器的一个基础。
Scheduler Configuration [1]
kube-scheduler 提供了配置文件的资源,作为给 kube-scheduler 的配置文件,启动时通过 --onfig= 来指定文件。目前各个kubernetes版本中使用的 KubeSchedulerConfiguration 为,
- 1.21 之前版本使用
v1beta1 - 1.22 版本使用
v1beta2,但保留了v1beta1 - 1.23, 1.24, 1.25 版本使用
v1beta3,但保留了v1beta2,删除了v1beta1
下面是一个简单的 kubeSchedulerConfiguration 示例,其中 kubeconfig 与启动参数 --kubeconfig 是相同的功效。而 kubeSchedulerConfiguration 与其他组件的配置文件类似,如 kubeletConfiguration 都是作为服务启动的配置文件。
| |
Notes:
--kubeconfig与--config是不可以同时指定的,指定了--config则其他参数自然失效 [2]
kubeSchedulerConfiguration使用
通过配置文件,用户可以自定义多个调度器,以及配置每个阶段的扩展点。而插件就是通过这些扩展点来提供在整个调度上下文中的调度行为。
下面配置是对于配置扩展点的部分的一个示例,关于扩展点的讲解可以参考kubernetes官方文档调度上下文部分
| |
Notes: 如果name="*" 的话,这种情况下将禁用/启用对应扩展点的所有插件
既然kubernetes提供了多调度器,那么对于配置文件来说自然支持多个配置文件,profile也是列表形式,只要指定多个配置列表即可,下面是多配置文件示例,其中,如果存在多个扩展点,也可以为每个调度器配置多个扩展点。
| |
scheduler调度插件 [3]
kube-scheduler 默认提供了很多插件作为调度方法,默认不配置的情况下会启用这些插件,如:
- ImageLocality:调度将更偏向于Node存在容器镜像的节点。扩展点:
score. - TaintToleration:实现污点与容忍度功能。扩展点:
filter,preScore,score. - NodeName:实现调度策略中最简单的调度方法
NodeName的实现。扩展点:filter. - NodePorts:调度将检查Node端口是否已占用。扩展点:
preFilter,filter. - NodeAffinity:提供节点亲和性相关功能。扩展点:
filter,score. - PodTopologySpread:实现Pod拓扑域的功能。扩展点:
preFilter,filter,preScore,score. - NodeResourcesFit:该插件将检查节点是否拥有 Pod 请求的所有资源。使用以下三种策略之一:
LeastAllocated(默认)MostAllocated和RequestedToCapacityRatio。扩展点:preFilter,filter,score. - VolumeBinding:检查节点是否有或是否可以绑定请求的 卷. 扩展点:
preFilter,filter,reserve,preBind,score. - VolumeRestrictions:检查安装在节点中的卷是否满足特定于卷提供程序的限制。扩展点:
filter. - VolumeZone:检查请求的卷是否满足它们可能具有的任何区域要求。扩展点:
filter. - InterPodAffinity: 实现Pod 间的亲和性与反亲和性的功能。扩展点:
preFilter,filter,preScore,score. - PrioritySort:提供基于默认优先级的排序。扩展点:
queueSort.
对于更多配置文件使用案例可以参考官方给出的文档
如何扩展kube-scheduler [4]
当在第一次考虑编写调度程序时,通常会认为扩展 kube-scheduler 是一件非常困难的事情,其实这些事情 kubernetes 官方早就想到了,kubernetes为此在 1.15 版本引入了framework的概念,framework旨在使 scheduler 更具有扩展性。
framework 通过重新定义 各扩展点,将其作为 plugins 来使用,并且支持用户注册 out of tree 的扩展,使其可以被注册到 kube-scheduler 中,下面将对这些步骤进行分析。
定义入口
scheduler 允许进行自定义,但是对于只需要引用对应的 NewSchedulerCommand,并且实现自己的 plugins 的逻辑即可。
| |
而 NewSchedulerCommand 允许注入 out of tree plugins,也就是注入外部的自定义 plugins,这种情况下就无需通过修改源码方式去定义一个调度器,而仅仅通过自行实现即可完成一个自定义调度器。
| |
插件实现
对于插件的实现仅仅需要实现对应的扩展点接口。下面通过内置插件进行分析
对于内置插件 NodeAffinity ,我们通过观察他的结构可以发现,实现插件就是实现对应的扩展点抽象 interface 即可。
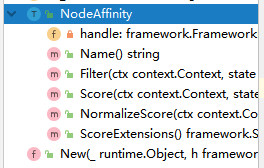
定义插件结构体
其中 framework.FrameworkHandle 是提供了Kubernetes API与 scheduler 之间调用使用的,通过结构可以看出包含 lister,informer等等,这个参数也是必须要实现的。
| |
实现对应的扩展点
| |
最后在通过实现一个 New 函数来提供注册这个扩展的方法。通过这个 New 函数可以在 main.go 中将其作为 out of tree plugins 注入到 scheduler 中即可
| |
实验:基于网络流量的调度 [7]
通过上面阅读了解到了如何扩展 scheduler 插件,下面实验将完成一个基于流量的调度,通常情况下,网络一个Node在一段时间内使用的网络流量也是作为生产环境中很常见的情况。例如在配置均衡的多个主机中,主机A作为业务拉单脚本运行,主机B作为计算服务运行。通常来说计算服务会使用更多的系统资源,而拉单需要更多的是网络流量,此时在调度时,默认调度器有限选择的是系统空闲资源多的节点,这种情况下如果有Pod被调度到该节点上,那么可能双方业务都会收到影响(前端代理觉得这个节点连接数少会被大量调度,而拉单脚本因为网络带宽的占用降低了效能)。
实验环境
- 一个kubernetes集群,至少保证有两个节点。
- 提供的kubernetes集群都需要安装prometheus node_exporter,可以是集群内部的,也可以是集群外部的,这里使用的是集群外部的。
- 对 promQL 与 client_golang 有所了解
实验大致分为以下几个步骤:
- 定义插件API
- 插件命名为
NetworkTraffic
- 插件命名为
- 定义扩展点
- 这里使用了 Score 扩展点,并且定义评分的算法
- 定义分数获取途径(从prometheus指标中拿到对应的数据)
- 定义对自定义调度器的参数传入
- 将项目部署到集群中(集群内部署与集群外部署)
- 实验的结果验证
实验将仿照内置插件 nodeaffinity 完成代码编写,为什么选择这个插件,只是因为这个插件相对比较简单,并且与我们实验目的基本相同,其实其他插件也是同样的效果。
整个实验的代码上传至 github.com/CylonChau/customScheduler
实验开始
错误处理
在初始化项目时,go mod tidy 等操作时,会遇到大量下面的错误
| |
kubernetes issue #79384 [5] 中有提到这个问题,粗略浏览下没有说明为什么会出现这个问题,在最下方有个大佬提供了一个脚本,出现上述问题无法解决时直接运行该脚本后正常。
| |
定义插件API
通过上面内容描述了解到了定义插件只需要实现对应的扩展点抽象 interface ,那么可以初始化项目目录 pkg/networtraffic/networktraffice.go。
定义插件名称与变量
| |
定义插件的结构体
| |
定义扩展点
因为选用 Score 扩展点,需要定义对应的方法,来实现对应的抽象
| |
接下来需要对结果归一化,这里就回到了调度框架中扩展点的执行问题上了,通过源码可以看出,Score 扩展点需要实现的并不只是这单一的方法。
| |
通过上面代码了解到,实现 Score 就必须实现 ScoreExtensions,如果没有实现则直接返回。而根据 nodeaffinity 中示例发现这个方法仅仅返回的是这个扩展点对象本身,而具体的归一化也就是真正进行打分的操作在 NormalizeScore 中。
| |
而在 framework 中,真正执行的操作的方法也是 NormalizeScore()
| |
下面来实现对应的方法
在 NormalizeScore 中需要实现具体的选择node的算法,因为对node打分结果的区间为 $[0,100]$ ,所以这里实现的算法公式将为 $最高分 - (当前带宽 / 最高最高带宽 * 100)$,这样就保证了,带宽占用越大的机器,分数越低。
例如,最高带宽为200000,而当前Node带宽为140000,那么这个Node分数为:$max - \frac{140000}{200000}\times 100 = 100 - (0.7\times100)=30$
| |
Notes:在kubernetes中最大的node数支持5000个,岂不是在获取最大分数时循环就占用了大量的性能,其实不必担心。scheduler 提供了一个参数
percentageOfNodesToScore。这个参数决定了这里要循环的数量。更多的细节可以参考官方文档对这部分的说明 [6]
配置插件名称
为了使插件注册时候使用,还需要为其配置一个名称
| |
定义PrometheusHandle
网络插件的扩展中还存在一个 prometheusHandle,这个就是操作prometheus-server拿去指标的动作。
首先需要定义一个 PrometheusHandle 的结构体
| |
有了结构就需要查询的动作和指标,对于指标来说,这里使用了 node_network_receive_bytes_total 作为获取Node的网络流量的计算方式。由于环境是部署在集群之外的,没有node的主机名,通过 promQL 获取,整个语句如下:
| |
整个 Prometheus 部分如下:
| |
定义调度器传入的参数
因为需要指定 prometheus 的地址,网卡名称,和获取数据的大小,故整个结构体如下,另外,参数结构必须遵循<Plugin Name>Args 格式的名称。
| |
为了使这个类型的数据作为 KubeSchedulerConfiguration 可以解析的结构,还需要做一步操作,就是在扩展APIServer时扩展对应的资源类型。在这里kubernetes中提供两种方法来扩展 KubeSchedulerConfiguration 的资源类型。
一种是旧版中提供了 framework.DecodeInto 函数可以做这个操作
| |
另外一种方式是必须实现对应的深拷贝方法,例如 NodeLabel 中的
| |
最后将其注册到register中,整个行为与扩展APIServer是类似的
| |
Notes:对于生成深拷贝函数及其他文件,可以使用 kubernetes 代码库中的脚本 kubernetes/hack/update-codegen.sh
这里为了方便使用了 framework.DecodeInto 的方式。
项目部署
准备 scheduler 的 profile,可以看到,我们自定义的参数,就可以被识别为 KubeSchedulerConfiguration 的资源类型了。
| |
如果需要部署到集群内部,可以打包成镜像
| |
部署在集群内部所需的资源清单
| |
启动自定义 scheduler,这里通过简单的二进制方式启动,所以需要一个kubeconfig做认证文件
| |
启动后为了验证方便性,关闭了原来的 kube-scheduler 服务,因为原来的 kube-scheduler 已经作为HA中的master,所以不会使用自定义的 scheduler 导致pod pending。
验证结果
准备一个需要部署的Pod,指定使用的调度器名称
| |
这里实验环境为2个节点的kubernetes集群,master与node01,因为master的服务比node01要多,这种情况下不管怎样,调度结果永远会被调度到node01上。
| |
而调度器的日志如下
| |
Reference
[2] kube-scheduler
[5] ssues #79384