Rebalance
当 Ceph 集群在扩容/缩容后,Ceph会更新 Cluster map, 在更新时会更新 Cluster map 也会更新 “对象的放置” CRUSH 会平均但随机的将对象放置在现有的 OSD 之上,在 Rebalancing 时,只有少量数据进行移动而不是全部数据进行移动,直到达到 OSD 与 对象 之间的平衡,这个过程就叫做 Ceph 的 Rebalance。
需要注意的是,当集群中的 OSD 数量越多,那么在做 Rebalance 时所移动的就越少。例如,在具有 50 个 OSD 的集群中,在添加 OSD 时可能会移动 1/50th 或 2% 的数据。
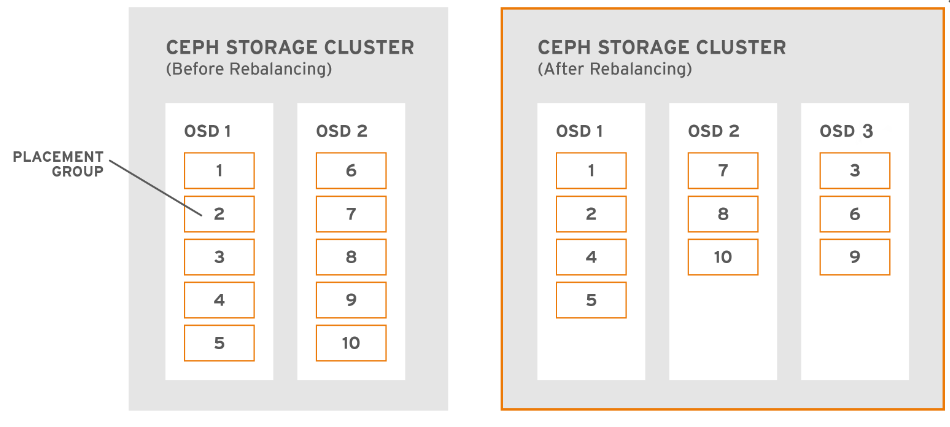
如下图所示,当前集群有两个 OSD,当在集群中添加一个 OSD,使其数量达到3时,这个时候会触发 Rebalance,所移动的数量为 OSD1 上的 PG3 与 OSD2 上的 PG 6和9
Balancer
执行 Rebalance 的模块时 Balancer,其可以优化 OSD 上的放置组 (PG) ,以实现平衡分配。
可以通过命令查看 balancer 的状态
| |
https://docs.ceph.com/en/latest/rados/operations/balancer/
Backfill
Ceph 回填 (Backfill) 指的是每当删除 OSD 时,Ceph 都会使用 “Backfill” 和 “recovery” 来重新 rebalance 存储集群。这样做是为了根据PG 策略保留数据的多个副本。这两个操作都会占用系统资源,因此当 Ceph 存储集群处于负载状态时,Ceph 的性能将会下降,因为 Ceph 将资源转移到 “回填” 和 “恢复” 过程。
有时为了在删除 OSD 时保持 Ceph 存储可接受的性能,需要先降低 “Backfill” 和 “recovery” 操作的优先级。降低优先级的代价是,较长时间内的数据副本较少,这将会导致数据面临风险。
回填和恢复的发生是发生在 OSD/节点 故障或新增时被触发,如果所有的回填同时发生,会对OSD带来很大的负载,这个现象叫做 ”雷群效应“ (“thundering herd” effect)
Configration backfill paramter
回填的参数通常位于 OSD 参数下,在 Ceph OSD 中关于 backfill [1] 的参数如下:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| osd_max_backfills | uint | 1 | 允许回填到单个 OSD 或从单个 OSD 回填的最大数量。请注意,这对于读和写操作是分开应用的。 |
| osd_backfill_scan_min | int | 64 | 每次回填扫描的最小对象数 |
| osd_backfill_scan_max | int | 512 | 每次回填扫描的最大对象数 |
| osd_backfill_retry_interval | float | 30.0 | 重试回填请求之前等待的秒数。 |
查看当前参数
查看配置之前需要确定 OSD 所在的节点,例如 OSD.1 可以通过 ceph osd tree 获取所有 OSD 列表
| |
在拿到 OSD 坐在节点可以通过下面命令查看对应的 OSD 配置
| |
接下来可以根据 OSD 类型(SSD, HDD, nvme) 的不同,来相应的调整,例如 NVMes 比 HDD 更好的性能,那么可以设置大的回填
| |
Recovery
如果 Ceph OSD 守护进程崩溃并重新上线,通常这个OSD会与 PG 中包含更新版本对象的其他 Ceph OSD 守护进程不同步。发生这种情况时,Ceph OSD 守护进程会进入恢复模式 (Recovery),并寻求获取最新的数据副本并使其映射恢复到最新状态。根据 Ceph OSD daemon 关闭的时间长短,OSD 的对象和 PG 可能会明显过时。此外,如果一个故障域(机架)发生故障,多个 Ceph OSD 守护进程可能会同时恢复在线状态。这会使恢复过程耗时且占用资源。
为了维持操作性能,Ceph 在执行恢复时限制恢复请求数量、线程和对象块大小,这使得 Ceph 在降级状态下也能良好运行。
恢复的参数通常位于 OSD 参数下,在 Ceph OSD 中关于 recovery [2] 的参数如下:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| osd_recovery_delay_start | float | 0.0 | peer互连完成后,Ceph 将延迟指定的秒数,然后再开始恢复 RADOS 对象。 |
| osd_recovery_max_active | uint | 0 | 每个 OSD 一次的活动恢复请求数。更多请求将加速恢复,但请求会增加集群的负载 |
| osd_recovery_max_active_hdd | uint | 3 | 如果主设备是旋转设备(HDD),则每个 OSD 一次的活动恢复请求数。 |
| osd_recovery_max_active_ssd | uint | 10 | 如果主设备是非旋转设备(即 SSD),则每个 OSD 一次的活动恢复请求数。 |
| osd_recovery_max_chunk | size | 8Mi | 恢复操作可以携带的数据块的最大总大小,需要注意单位。 |
| osd_recovery_max_single_start | uint | 1 | 当 OSD (daemon)恢复时,每个 OSD 新启动的恢复操作的最大数量。 |
| osd_recovery_sleep | float | 0.0 | 在下一次“恢复”或“回填”操作之前休眠的时间(以秒为单位)。增加此值将减慢恢复操作,而客户端操作受影响较小。 |
| osd_recovery_sleep_hdd | float | 0.1 | HDD 下次恢复或回填操作之前的睡眠时间(以秒为单位)。 |
| osd_recovery_sleep_ssd | float | 0.0 | SSD 下一次恢复或回填操作之前的睡眠时间(以秒为单位)。 |
| osd_recovery_sleep_hybrid | float | 0.025 | 当 OSD 数据位于 HDD 上并且 OSD 日志/WAL+DB 位于 SSD 上时,在下一次恢复或回填操作之前休眠的时间(以秒为单位)。 |
| osd_recovery_priority | uint | 5 | 为恢复工作队列设置的默认优先级。与 Pool 无关 |
Ceph backfill 和 recovery 也可以在 Ceph dashboard 中进行配置
异步恢复
在 Nautilus 版本之前 “恢复” 动作是同步的,同步最显著的一个特征就是 “同步时会阻止对 RADOS 对象的写入,直到恢复为止”。
回填操作与恢复操作有些不同,回填会临时分配不同的活动集(Active set, PG的一个属性),并回填活动集之外的 OSD 来允许继续写入
而为了避免 “同步恢复” 的问题 Ceph 提供了一种可以异步恢复的配置,当异步恢复发生时,对活动集成员可继续写入,有关于更多的异步说明,可以参考 Ceph 文档 asynchronous recovery 部分
Reference
[1] backfilling
[2] recovery