本文记录了在 kubernetes 环境中,使用 cephfs 时当启用了 fscache 时,由于网络问题,或者 ceph 集群问题导致的整个 k8s 集群规模的挂载故障问题。
结合fscache的kubernetes中使用cephfs造成的集群规模故障
在了解了上面的基础知识后,就可以引入故障了,下面是故障产生环境的配置
故障发生环境
| 软件 | 版本 |
|---|---|
| Centos | 7.9 |
| Ceph | nautilus (14.20) |
| Kernel | 4.18.16 |
故障现象
在 k8s 集群中挂在 cephfs 的场景下,新启动的 Pod 报错无法启动,报错信息如下
| |
主要表现的现象大概为如下三个特征
对于该节点故障之前运行的 Pod 是正常运行,但是无法写入和读取数据
无法写入数据 permission denied

无法读取数据

kublet 的日志报错截图如下
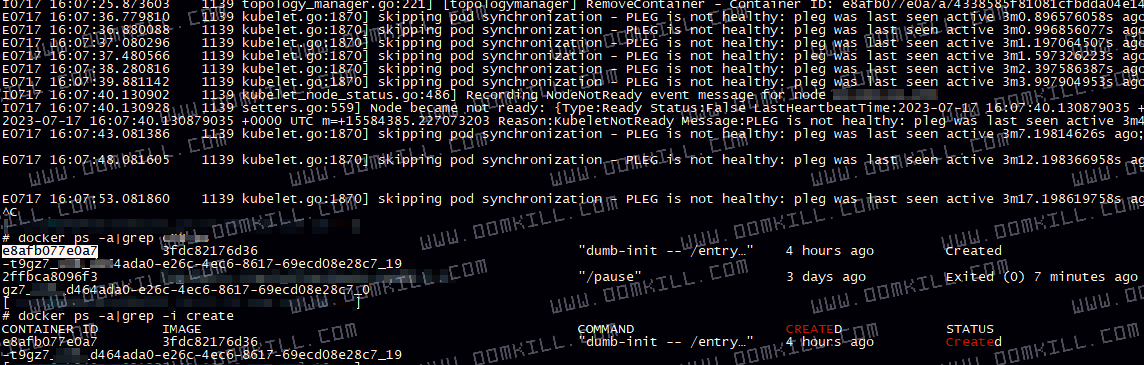
彻底解决方法
需要驱逐该节点上所有挂在 cephfs 的 Pod,之后新调度来的 Pod 就可以正常启动了
故障的分析
当网络出现问题时,如果使用了 cephfs 的 Pod 就会出现大量故障,具体故障表现方式有下面几种
新部署的 Pod 处于 Waiting 状态
新部署的 Pod 可以启动成功,但是无法读取 cephfs 的挂载目录,主要故障表现为下面几种形式:
- ceph mount error 5 = input/output error [3]
- cephfs mount failure.permission denied
旧 Pod 无法被删除
新部署的 Pod 无法启动
注:上面故障引用都是在网络上找到相同报错的一些提示,并不完全切合本文中故障描述
去对应节点查看节点内核日志会发现有下面几个特征

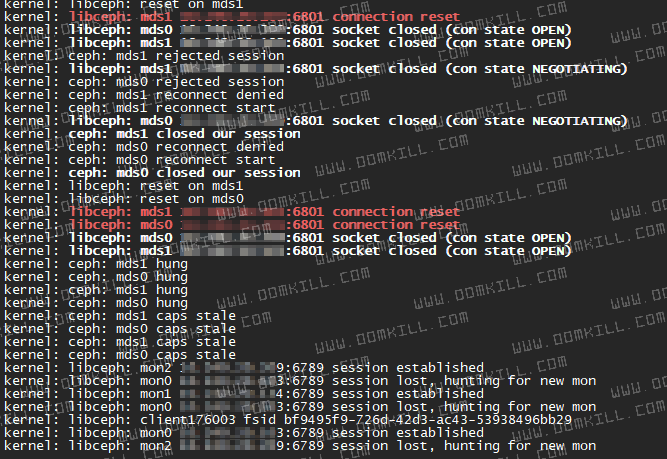
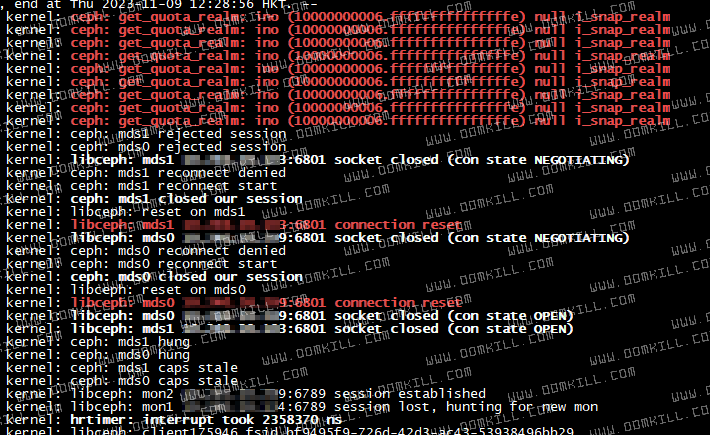
| |
故障分析
由上面的三张图我们可以得到几个关键点
- connection reset
- session lost, hunting for new mon
- ceph: get_quota_realm()
- reconnection denied
- mds1 hung
- mds1 caps stale
这三张图上的日志是一个故障恢复的顺序,而问题节点(通常为整个集群 Node)内核日志都会在刷 ceph: get_quota_realm() 这种日志,首先我们需要确认第一个问题,ceph: get_quota_realm() 是什么原因导致,在互联网上找了一个 linux kernel 关于修复这个问题的提交记录,通过 commit,我们可以看到这个函数产生的原因
get_quota_realm() enters infinite loop if quota inode has no caps. This can happen after client gets evicted. [4]
这里可以看到,修复的内容是当客户端被驱逐时,这个函数会进入无限 loop ,当 inode 配额没有被授权的用户,常常发生在客户端被驱逐。
通过这个 commit,我们可以确定了后面 4 - 6 问题的疑问,即客户端被 ceph mds 驱逐(加入了黑名单),在尝试重连时就会发生 reconnection denied 接着发生陈腐的被授权认证的用户 (caps stale)。接着由于本身没有真实的卸载,而是使用了一个共享的 cookie 这个时候就会发生节点新挂载的目录是没有权限写,或者是 input/output error 的错误,这些错误表象是根据不同情况下而定,比如说被拉黑和丢失的会话。
kubelet的错误日志
此时当新的使用了 volumes 去挂载 cephfs时,由于旧的 Pod 产生的工作目录 (/var/lib/kubelet) 下的 Pod 挂载会因为 cephfs caps stale 而导致无法卸载,这是就会存在 “孤儿Pod”,“不能同步 Pod 的状态”,“不能创建新的Pod挂载,因为目录已存在”。
kubelet 日志如下所示:
| |
问题复现
节点:192.168.155.70
操作步骤,手动删除掉这个节点的会话复现问题:
操作前日志
| |
步骤一:查找客户端id
| |
步骤二:驱逐该客户端
| |
步骤三:检查客户端
查看日志,与 Openstack 全机房故障出现时日志内容一致
| |
问题建议与解决
- 取消fscache,但fscache的存在是为了实现大并发连接ceph的机制,取消比较困难
- 调整参数(还没有测试):当网络异常时,保证不要拉黑客户端使其可以重连,这里理论上可以解决客户端缓存问题
首先上面我们阐述了问题出现背景以及原因,要想解决这些错误,要分为两个步骤:
- 首先驱逐 Kubernetes Node 节点上所有挂载 cephfs 的 Pod,这步骤是为了优雅的结束 fscache 的 cookie cache 机制,使节点可以正常的提供服务
- 解决使用 fscache 因网络问题导致的会话丢失问题的重连现象
这里主要以步骤2来阐述,解决这个问题就是通过两个方式,一个是不使用 fscache,另一个则是不让 mds 拉黑客户端,关闭 fscache 的成本很难,至今没有尝试成功,这里通过配置 ceph 服务使得 ceph mds 不会拉黑因出现网络问题丢失连接的客户端。
ceph 中阐述了驱逐的概念 “当某个文件系统客户端不响应或者有其它异常行为时,有必要强制切断它到文件系统的访问,这个过程就叫做驱逐。” [5]
问题的根本原因为:ceph mds 把客户端拉入了黑名单,缓存导致客户端无法卸载连接,但接入了 fscache 的概念导致旧 session 无法释放,新连接会被 reject。
要想解决这个问题,ceph 提供了一个参数来解决这个问题,mds_session_blacklist_on_timeout
It is possible to respond to slow clients by simply dropping their MDS sessions, but permit them to re-open sessions and permit them to continue talking to OSDs. To enable this mode, set
mds_session_blacklist_on_timeoutto false on your MDS nodes. [6]
最终在配置后,上述问题解决
解决问题后测试故障是否存在
测试过程
ceph 参数的配置

操作驱逐 192.168.155.70 的客户端连接,用以模拟 ceph 运行的底层出现故障而非正常断开 session 的场景

重新运行 Pod 检查 session 是缓存还是会重连

附:ceph mds 管理客户端
查看一个客户端的连接
| |
手动驱逐一个客户端
| |
查看 ceph 的配置参数
| |
查看黑名单
| |
查看客户端连接
| |
If you are experiencing frequent client evictions, due to slow client hosts or an unreliable network, and you cannot fix the underlying issue, then you may want to ask the MDS to be less strict.
| |
当出现问题无法卸载时应如何解决?
当我们遇到问题时,卸载目录会出现被占用情况,通过 mount 和 fuser 都无法卸载
| |
这个时候由于 cephfs 挂载问题会导致整个文件系统不可用,例如 df -h, ls dir 等,此时可以使用 umount 的懒卸载模式 umount -l,这会告诉内核当不占用时被卸载,由于这个问题是出现问题,而不是长期占用,这里用懒卸载后会立即卸载,从而解决了 stuck 的问题。
什么是fscache
fscache 是网络文件系统的通用缓存,例如 NFS, CephFS都可以使用其进行缓存从而提高 IO
FS-Cache是在访问之前,将整个打开的每个 netfs 文件完全加载到 Cache 中,之后的挂载是从该缓存而不是 netfs 的 inode 中提供
fscache主要提供了下列功能:
- 一次可以使用多个缓存
- 可以随时添加/删除缓存
- Cookie 分为 “卷”, “数据文件”, “缓存”
- 缓存 cookie 代表整个缓存,通常不可见到“网络文件系统”
- 卷 cookie 来表示一组 文件
- 数据文件 cookie 用于缓存数据
下图是一个 NFS 使用 fscache 的示意图,CephFS 原理与其类似
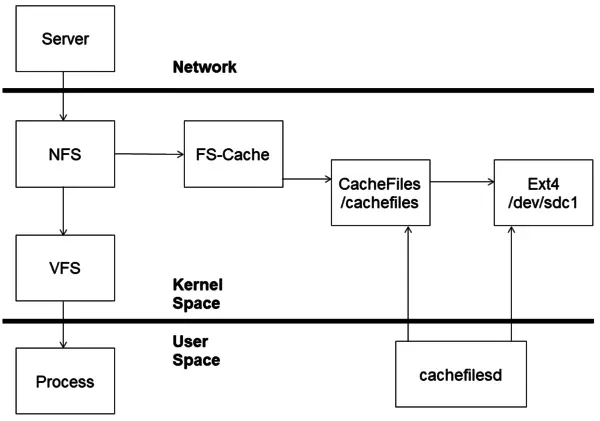
CephFS 也是可以被缓存的一种网络文件系统,可以通过其内核模块看到对应的依赖
| |
在启用了fs-cache后,内核日志可以看到对应 cephfs 挂载时 ceph 被注册到 fscache中
| |
当 monitor / OSD 拒绝连接时,所有该节点后续创建的挂载均会使用缓存,除非 umount 所有挂载后重新挂载才可以重新与 ceph mon 建立连接
cephfs 中的 fscache
ceph 官方在 2023年11月5日的一篇博客 [1] 中介绍了,cephfs 与 fscache 结合的介绍。这个功能的加入最显著的成功就是 ceph node 流向 OSD 网络被大大减少,尤其是在读取多的情况下。
这个机制可以在代码 commit 中看到其原理:“在第一次通过文件引用inode时创建缓存cookie。之后,直到我们处理掉inode,我们都不会摆脱cookie” [2]